The Context Layer: Where Agentic AI Still Falls Short
The Bottleneck for Agentic AI Isn't Capability. It's Context.

I have spent the last twelve months watching the agentic AI conversation from an unusually direct vantage point. I see close to two hundred companies across the Fuel Ventures portfolio — many of them building, deploying, and trying to operationalise agents inside real businesses. I sit in investment calls where founders pitch the next autonomous workflow. I read earnings calls where public software companies try to articulate their AI strategy. I run an AI stack across my own firm. From that vantage point, one pattern is now unmistakable.
Agents that look extraordinary in a demo collapse the moment they are pointed at real work inside a real company. That gap — between what agents do in controlled environments and what they do inside an operational business — is the most important story in AI right now. Not because the technology isn’t real. It is. But because the limits we keep running into are no longer limits of the model. But limits on context.
Tom Blomfield (Co-Founder of Monzo) captured it well recently. He described the experience of deploying agents as something like “replacing 90% of your employees with a team of geniuses who have no idea how your company operates. Total chaos. Nothing works”. The image is vivid, but what’s more interesting is how quickly the rest of the industry chimed in to agree.

Garry Tan, the President of Y Combinator, responded by calling it “the actual bottleneck” - the models, in his words, are smart enough already; what’s missing is the company-specific context locked in senior people’s heads, and the unlock is whoever cracks knowledge extraction at the company level. Marc Andreessen has been making a structurally similar argument for the better part of a year — that the constraint on enterprise AI is no longer model capability, but the absence of the integration, data, and contextual scaffolding that lets capability actually do anything inside a real business. Aaron Levie at Box keeps repeating the same point in slightly more practical terms: the AI is fine, but the AI doesn’t know your company, and that’s where every deployment breaks when running perpetually.
When four independent voices from very different parts of the AI ecosystem converge on the same diagnosis within a few weeks, it’s usually a signal worth following. The problem isn’t intelligence. The problem is context — and we have, collectively, dramatically underinvested in solving it.
This piece is an attempt to lay out where agentic AI is genuinely falling short today, why it’s falling short, and what that tells us about the next layer of value creation in this cycle. The interesting story is not that agents don’t work. It’s that they don’t work yet, in production, at the scale the headlines imply. The reason is structural. And the companies that solve it will be among the most important built in this decade.
1. The Demo-to-Production Gap
The agentic AI category is, depending on how you frame it, somewhere between two and four years old. In that time, the public face of it has been almost entirely defined by demos. A model writes an entire app. An AI agent books travel. A swarm of agents runs a fake marketing department. The artefacts are impressive and they shape the expectations of everyone watching, from investors to operators to enterprise buyers.
But there’s an important asymmetry that often gets lost. A demo is designed to compress complexity. A production environment is designed to expose it. A demo runs once, on a pre-defined path, with clean inputs and a curated tool set. A production system runs millions of times, on messy inputs, with edge cases, conflicting policies, partial data, and silent state. Demos sell the dream. Production has to deliver it.
This is not a new pattern. Every major technology cycle has followed roughly the same arc: an early period defined by spectacular demos, followed by a much longer, less glamorous slog of operationalisation. Cloud took the better part of a decade to evolve from “we can rent servers on demand” into the integrated infrastructure backbone that runs the modern economy. SaaS travelled a similar gradient from departmental tools to mission-critical systems of record. Mobile did the same. The pattern is consistent: capability gets demonstrated, expectations get set, and the substantive work happens in the long tail — invisible to everyone except the operators who live inside it.
What’s different about agentic AI is the magnitude of the gap. The capability ceiling is higher than in any prior cycle — these systems can reason, plan, and act across multi-step problems in ways earlier software could not — but the operational floor is correspondingly lower, because agents are stateful, probabilistic, and non-deterministic by design. A SaaS product either works or it doesn’t; its failure modes are binary and visible. An agent can work, partially work, or produce a confident, well-formed output that is materially wrong — and the only reliable way to discover which has happened is to deploy it inside a live process and observe.
The result is a market populated by organisations that have run successful pilots, but only a few have deployed agents into anything resembling material operational scale. The agents that do scale tend to share a profile: narrow scope, low-stakes outputs, well-understood failure modes. Tier-one support queries. Outbound email drafting. Call summarisation. This is still useful, but not the end-state. The common thread is that the task surface is small, the tooling is bounded, and the cost of a wrong answer is recoverable. That isn't a criticism — it's a description of where the operational frontier currently sits. Agents perform reliably in the regions of a process where the context required is shallow, the available tools are clearly defined, and the consequences of error are bounded. Move any of those variables — deepen the context, widen the toolset, raise the stakes — and the system begins to degrade.
The interesting question isn’t whether this will change. It will. The interesting question is what has to change for it to change.
2. The Missing Context Layer
If you talk to anyone actually shipping agents inside an enterprise you eventually hear the same complaint. The model is fine. The tools are fine. The infrastructure is fine. What’s missing is context.
This is what Blomfield, Tan, Levie and Andreessen were each pointing at. Imagine hiring a team of brilliant graduates and dropping them into your company with no onboarding, no documentation, no manager, no Slack history, and no understanding of how anything actually works. They will be eager. They will be capable. They will also be useless, in a very specific way — they will confidently do the wrong things, because they don’t know what the right things are.
That is the experience of deploying an off-the-shelf agent inside most companies today. The agent can read. The agent can act. The agent can reason. But it has no sense of the implicit knowledge that shapes how decisions actually get made — the unwritten policies, the historical context, the specific way this team handles this kind of edge case, the customer segments that get treated differently for reasons no one bothered to document.
What enterprises are slowly realising is that the model is a generalist intelligence, and the company is a specialist environment. The model knows a lot about the world. It knows almost nothing about your business — not because it’s poorly trained, but because the information it would need has never been written down anywhere it could read. Fine-tuning, the obvious technical objection, only takes you part of the way. It can teach a model the language, format, and tonal patterns of a business, but it cannot give the model live access to the operational state of the company — and the deeper problem, that most of the necessary information has never been written down at all, is upstream of fine-tuning, RAG, or any other technique that assumes the data already exists. You cannot train a model on something that does not yet exist.
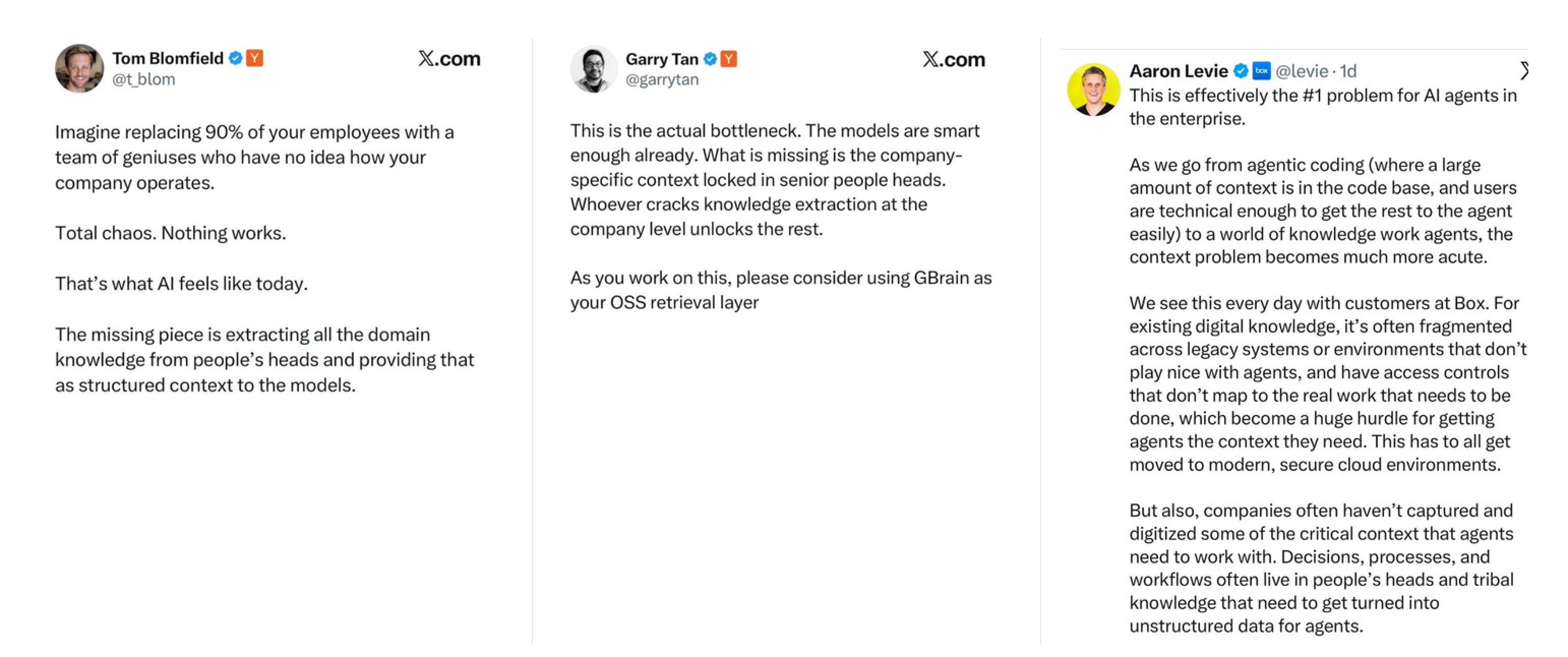
This is the layer that has been missing from the AI stack. Foundation models supply raw capability. Orchestration layers manage flow and coordination. Applications package up workflows. None of them solve the context problem. None of them turn the messy, distributed, mostly tacit knowledge of an organisation into something a model can consume.
You can see this gap clearly in the failure modes of early enterprise agents. The agent retrieves the wrong document because it doesn’t know which version of a policy is authoritative. It escalates a low-value issue because it doesn’t know that this particular customer sits in a special tier. It drafts a contract clause that violates an internal standard that exists only in the head of one senior partner. None of these are failures of intelligence. They are failures of context.
What’s notable is that this is not a model problem. Better models will not solve it on their own. A more capable agent placed inside a context-poor environment is, if anything, a worse agent — it acts more decisively on the wrong information. The constraint is not the brain. The constraint is the world the brain is operating in. The companies that build this layer early own a durable moat. Once an organisation has a structured, machine-readable representation of its own operational knowledge — its policies, workflows, edge cases, decision rights, historical precedent — that representation becomes the differentiation. The model is a swappable component. The context substrate is what compounds. This is where the data flywheel begins to turn in earnest. Every interaction that runs through the context substrate generates new signal — a corrected output, a captured edge case, an override that surfaces an unwritten rule. Each one feeds back into the context layer, sharpening the next decision and pulling more workflow into the system. The model layer cannot generate this loop on its own. The substrate can, and that is the moat.
When you decompose what "context" actually means in operational terms, the scope becomes obvious. It includes the company's authoritative version of every internal policy. The history of every customer relationship. The hierarchy of which decisions need which approvals. The map of who owns what and who is allowed to do what. The catalogue of edge cases and the way they have historically been handled. The semantic relationships between concepts that only make sense inside this particular business. None of this is exotic information. All of it is necessary. Almost none of it is captured anywhere a model can read.
3. The Tacit Knowledge Problem
The reason the context layer is so hard to build is that most of the knowledge inside a company is not, in any meaningful sense, written down. This is a point that’s been made for decades in the management literature — Michael Polanyi called it tacit knowledge, the kind we know but cannot fully articulate — but it has new force in the agentic era.
The textbook view of an enterprise is that operations run on documented processes, captured policies, structured data, and standardised playbooks. The reality is that they run on heuristics, hallway conversations, accumulated judgement, and decisions made by people who happen to have been there a long time. Anyone who has ever worked inside both large and small organisations knows this. Most of the institutional intelligence sits in heads, not in systems.
This is a problem because models cannot read minds. They can read documents, transcripts, logs, and schemas, but they cannot infer what an experienced operator simply knows. The instinct that a particular customer is about to churn. The unspoken rule that contracts above a certain size always get reviewed by legal even if policy says otherwise. The understanding that a particular vendor’s invoices are unreliable and need a second look. None of this lives anywhere a model can find it.
The companies starting to make real progress with agents are doing something specific about this. They are treating knowledge extraction as a first-order engineering discipline — not a documentation exercise. They are interviewing operators systematically. They are mining call recordings, support tickets, and Slack channels for patterns. They are turning the implicit into the explicit, and then turning the explicit into something structured enough that a model can act on it.
This is harder than it sounds. The difficulty isn’t the act of writing things down — it’s knowing what you don’t know. Most organisations don’t have a clear sense of which decisions are governed by formal policy and which are governed by tacit judgement, because the people making the tacit decisions usually don’t realise they’re doing it. They’ve internalised the heuristics so deeply that they no longer experience them as choices. What this means in practice is that building a usable context layer is, in part, an act of organisational introspection. You have to interrogate how work actually happens, not how the org chart says it happens. You have to surface the tribal knowledge before you can structure it. You have to be willing to discover that the official process and the real process diverge — sometimes significantly.
I've experimented with a version of this at personal scale over the last year — building what I think of as a structured second brain in Obsidian, capturing how I think about deals, the frameworks I rely on, books I’ve read, the patterns I'm seeing across the portfolio, the heuristics I use when underwriting. The exercise is genuinely difficult, and not because the tooling is hard. It is difficult because most of what I actually know about venture, AI, or any other domain I work in lives in my head as instinct rather than as articulated principle. Extracting it requires a discipline that doesn't come naturally — interrogating my own decisions, naming heuristics I didn't realise I was using, writing down the things I would otherwise just do. If the exercise is this difficult at the scale of one person, the scale of an organisation is an order of magnitude harder, and the scale of a Fortune 500 is harder still.
This is the unglamorous part of AI enablement. It produces no clean demos and no measurable productivity bump in the first quarter. But it is the precondition for everything else. The companies treating knowledge extraction as a first-order engineering discipline are building the asset that determines whether their agents will eventually do real work both perpetually and autonomously.
4. Memory, State, and Continuity
The second structural gap that agentic AI keeps running into is memory, state and continuity. Agents, as they exist today, are mostly stateless. They start. They run. They finish. They forget. That’s an oversimplification, but not by much. A typical agent has a context window, a session memory, and maybe a small persistent store of recent interactions. What it does not have, in any robust sense, is continuity. It does not remember last week. It does not know what it tried yesterday. It does not have a sense of identity that persists across tasks. Every interaction starts close to zero.
This is fine for the kinds of agents we’ve been deploying so far — narrow, short-lived, single-purpose. It is not fine for the kinds of agents we keep being told are around the corner: long-running, multi-step, embedded into actual operations. Those agents require memory in a way that the current stack does not natively support, and the workarounds people are using to fake it are starting to creak.
You can see this in the way long-running agentic tasks break down. An agent kicks off a multi-day workflow — researching a market, building a deliverable, coordinating across systems — and somewhere in the middle, state is lost. A retry happens. A handoff fails. A new session is spawned with incomplete history. The agent ends up doing duplicate work, or skipping critical steps, or producing inconsistent outputs because it can’t remember what it already concluded.
The problem is partly technical and partly conceptual. Technically, we don’t yet have great primitives for durable, queryable agent memory. The infrastructure people are building — vector stores, graph databases, episodic memory systems — is real and useful, but it’s also early and fragmented. Conceptually, we haven’t really agreed on what agent memory should look like. Is it a log? A graph? A summary? A learned representation? Everyone is still experimenting.
Memory is one half of the problem. State is the other. Even if an agent could remember everything it had ever done, real business processes are rarely a single action — they are multi-step sequences that pause, branch, wait for approvals, fail partway through, and require recovery. An invoice gets generated, sits in a queue, gets rejected, gets revised, gets re-approved, gets posted. A sales process runs across email, the CRM, a contract tool, and a billing system, with handoffs and dependencies at every step. Agents today do not natively handle this kind of mid-process complexity. The orchestration layer is beginning to absorb some of it, but the underlying primitives — durable checkpoints, clean resumption after failure, guarantees against the same step running twice — are still being figured out.
This is a point Andrej Karpathy has made repeatedly over the last year: the reason agents don’t yet work the way the hype suggests is not that the models are too weak — it’s that we haven’t figured out how to give them durable memory, working state, and a coherent sense of what they did last time. He’s framed the next phase of AI as fundamentally a systems problem, not a model problem. That’s exactly the right framing, and it applies as much to the agentic frontier as it does to anything else in the stack. The bigger picture here is that businesses don’t run on tasks. They run on processes that extend across time.
This software-level memory problem has a hardware mirror. I wrote earlier this year, in my breakdown of Coatue's market report, that the memory complex — Micron, SK Hynix, Samsung — is capturing more of the agentic rotation than the consensus shortage narrative credits, because agentic context windows and persistent memory are RAM and HBM intensive. As the software stack starts to demand durable, queryable agent memory at scale, the hardware substrate underneath has to expand to support it. The two layers are tracking the same underlying transition. Agents need to remember — and remembering at scale, at both the silicon level and the system level, is expensive.
5. The Reliability and Trust Tax
Even if you solve context and you solve memory, there is a third structural problem waiting for you on the other side. It’s the one that, in my experience, separates companies that have deployed agents in pilots from companies that have deployed agents in production. It is the trust problem, and it has nothing to do with marketing trust or PR — it has to do with operational trust, the kind that determines whether a business is willing to let an agent take consequential action on its behalf.
The honest reality is that no enterprise of meaningful size will hand over consequential workflows to a system it does not deeply understand and cannot deeply control. That is not a failure of imagination. It is a basic feature of how serious businesses operate. They have auditors. They have regulators. They have customers who will sue them. They have boards. The cost of getting something wrong inside the wrong workflow is often catastrophic, and no amount of model improvement on its own changes that calculus.
This is why so much of the agentic AI conversation, when it leaves the demo stage and enters the enterprise, ends up being about evaluation, observability, governance, fallbacks, and human-in-the-loop design. These topics are dull. They are also the difference between a system that gets deployed and a system that doesn’t. Most current agents do not have a coherent answer here. They are evaluated, when they are evaluated at all, using narrow benchmarks that bear little resemblance to the messiness of real-world performance. They are deployed without a robust way to monitor drift. They are corrected by retraining or re-prompting, rather than by structured feedback loops.
Air Canada provides a real life case study of what happens when this infrastructure is missing. A customer asked the airline's chatbot about bereavement fares; the chatbot fabricated a policy that did not actually exist. When the customer later tried to claim the fare, Air Canada refused, arguing that the chatbot was effectively a separate legal entity. A small claims tribunal disagreed, ruling that the company was responsible for everything its AI said. The judgment was small in financial terms — a few hundred dollars. The implication was not. Every enterprise CIO watching that case understood it as the moment their general counsel started asking different questions about every AI deployment in the pipeline.
Inside the AI labs themselves, the gap Air Canada exposed is increasingly being named directly. Dario Amodei has been the most candid about it. He has argued that the distance between a model that can perform a task and a model an enterprise will actually trust to perform that task unsupervised is structurally far wider than most of the industry acknowledges — and that closing it is not a pre-training problem. It requires deliberate investment in interpretability, evaluation, and the operational harness around the model.
The operating assumption, for now, is that the right deployment posture for almost every agent is collaborative — not fully autonomous — and that getting to autonomy is a function of accumulated trust, not raw capability. The right way to frame the economics of this is as a reliability tax. Today, that tax is enormous: to deploy a meaningful agent inside a real business, you have to invest as much in the verification surface as you do in the agent itself. That ratio will compress over time — the orchestration layer I have written about previously absorbs some of the cost — but it will not disappear. Trust is not a feature you ship. It is a system you build.
6. What History Tells Us About the Direction of Travel
Every prior tech cycle has run through the same pattern. A new capability arrives, captures the imagination, drives a phase of dramatic infrastructure build-out, and then commoditises. Once the capability commoditises, the value migrates upward — to the layer that organises it, packages it, and embeds it inside actual operational systems. The companies that captured the first phase rarely captured the second. The companies that captured the second became the defining businesses of the cycle.
This is not a new observation. As I covered before, Carlota Perez has been making a version of it across industrial cycles for decades — her work on technological revolutions describes precisely this migration of value, once a new capability commoditises, from the layer that delivers it into the layer that organises it. What is unusual about the AI cycle is the speed at which it is playing out, and the specific layer the value is migrating into.
The first wave of cloud was about raw compute. For roughly a decade after AWS launched, the question was whether enterprises would trust someone else’s servers (cloud vs on-prem). Once they did, the IaaS layer commoditised quickly — Azure and GCP closed the gap, prices fell, and the differentiation moved upward. The companies that compounded value through the back half of the cloud cycle were the ones building on top of commoditised compute: Snowflake, Databricks, Datadog, MongoDB, Stripe. The layer that mattered was no longer the servers. It was the layer of managed services, data infrastructure, and operational tooling that turned commoditised compute into operational reality.
SaaS followed the same trajectory. The first wave was about replacing on-premise software with browser-delivered alternatives. By the early 2010s, that proposition was no longer novel — every category had a SaaS contender, and horizontal applications became increasingly commoditised. The companies that broke out from the middle of the decade onward were vertical: Veeva in life sciences, Procore in construction, Toast in restaurants, ServiceTitan in trades. They captured value by going narrow, owning the domain context, and embedding into workflows horizontal SaaS could never quite reach. The layer of vertical domain knowledge became more valuable than the SaaS layer that sat on top of it.
Mobile played out similarly. The first wave was about the OS — iOS versus Android, who would win the platform. By the early 2010s the platforms were set, and the OS itself had become commoditised infrastructure. The companies that captured the second decade of mobile value were not the OS builders; they were the ones who owned the layer the OS gave them access to: identity (Auth0, Okta), location (Mapbox, the mapping layer underneath Uber), payments (Stripe, Adyen). The platform got cheaper and more uniform. The layer above it got more valuable.
AI is now running the same arc, considerably faster. The capability — large language models — went from research curiosity to enterprise table stakes in roughly thirty months. The frontier labs are in a race that increasingly resembles the cloud-vendor wars of 2010: a small number of well-capitalised players, narrowing technical differentiation, and structural price compression on the horizon. Model capability will continue to compound, but its differentiation as a business advantage is already eroding. What sits above it — context, memory, orchestration, and trust — is where the layered logic of every prior cycle says the next decade of value will accrue. This is the context layer the rest of the article has been describing.
There is one important nuance this time. In prior cycles, the commoditising layer and the layer above it were broadly stacked vertically. In AI, the two layers are moving in opposite directions at the same time. The model layer is consolidating — toward three to five frontier labs that will capture the majority of foundation-model economics. The context layer is fragmenting in the opposite direction, across thousands of vertical context substrates, each with its own structured representation of operational reality. The model and the company are, in effect, decoupling. The model becomes shared infrastructure. The context layer becomes the part of the stack that distinguishes one business from another. I think the most interesting opportunities of the next decade will sit at the seam between those two layers — close enough to the model to benefit from its compounding capability, far enough from it to own the context layer that turns capability into competitive advantage.
You can already see the visible candidates positioning themselves on both sides of this decoupling. On the horizontal side, Databricks and Snowflake are racing to own the data layer underneath every enterprise agent — Databricks through Mosaic AI and Unity Catalog, Snowflake through Cortex. Glean has built the connective tissue between fragmented SaaS tools and the agents trying to read from them, turning enterprise search into a permission-aware knowledge graph that becomes the foundation every internal agent operates on. On the vertical side, Sierra is building the brand-specific, policy-aware customer-experience layer that lets agents represent a business inside its own operational reality. Abridge is doing the same in clinical documentation, Harvey in legal, Cresta in contact centres. None of these are model companies. All of them are context-layer companies — building, in real time, the layer underneath the AI economy.
Look fwd to digesting