From 'Token Maxing' to Token Efficiency in the Agentic Era
Volume is exploding. Per-token cost is collapsing.

For most of the last three years, the dominant question inside any company deploying AI has been a simple one: how do we get access to the best model, and how do we use as much of it as possible? The era of generative AI began as an era of token maxing. The frontier model was the differentiator. Cost was an afterthought. The competitive instinct was to throw more capability at every workflow until the output was unrecognisable from what came before.
That regime is ending. The models are getting better, faster, and cheaper than at any point in the history of computing — but the economic structure of how organisations consume tokens has fundamentally changed. Volume is exploding. Agentic workflows now burn one to two orders of magnitude more compute than chat interactions ever did. And the companies that came of age in the token-maxing era are confronting an uncomfortable reality: their cost of intelligence is no longer trivial, and managing it is becoming a first-order operating discipline.
The shift now underway is from token maxing to token efficiency. From “use the best model” to “use the right model.” From “more capability per request” to “lower cost per outcome.” This is one of the most important structural transitions in enterprise AI. This article lays out where token economics is heading, why agentic workloads are the forcing function, the operating discipline emerging around them, and why the deeper question is not how to spend less, but how to spend better.
1. The Inflection Point — From Token Maxing to Token Efficiency
The first phase of the generative AI cycle had a recognisable shape. The early adopter playbook was straightforward: pick the most capable frontier model, give it as much context as possible, let it generate as long as it needed, and pay whatever the bill came to. The token bill was a rounding error compared to the value being unlocked. The competitive question was not how to use AI efficiently — it was how to use it at all.
That worked because the volume was manageable. A few thousand prompts a day, a handful of long-context summarisations, a sales team using ChatGPT for outbound — these were rounding errors against a P&L denominated in millions. The token cost of running AI was, for almost every enterprise deployment in 2023 and most of 2024, a few hundred dollars a month. Nobody optimised. Nobody routed. Nobody much cared.
That world is rapidly disappearing. Three forces are reshaping it.
The first is volume. Token throughput is compounding at a rate no input commodity has ever sustained. Coatue’s data has the major API providers running at roughly twelve times the token volume year on year — an order of magnitude faster than Moore’s Law ever delivered. Google’s reported token processing went from 980 trillion to 1.3 quadrillion in two months. The substrate of the AI economy is consuming raw material at a rate the existing infrastructure was not built to deliver.
The second is the shift to agentic workloads. A casual user of ChatGPT might burn fifty thousand tokens in a session. A single autonomous agent task — running a research query, building a deliverable, executing a multi-step workflow — can burn one to two million. That is not a marginal increase. It is two to three orders of magnitude, and it compounds across every agent run in production. Every company moving from chat to agents is, in effect, multiplying its token consumption by something close to a thousand without realising it until the bill arrives.
The third is the maturing economics of the application layer. As AI moves from the experimentation budget into the core operating cost base, finance teams start asking different questions. Token spend stops being a research-and-development line item and starts showing up in gross margin discussion. CFOs who previously waved through six-figure OpenAI bills are now asking what the cost per inference is, what the cost per active user is, what the cost per resolved customer ticket is. The discipline of unit economics is arriving at the AI layer.
The combination of these three forces is producing a real and consequential reframing. The competitive question is no longer “how much AI can we use?” It is “how cheaply can we run the AI we use?” Token efficiency is now becoming a board-level operating concern.
This is not a hypothetical shift. Anthropic hit a capacity wall earlier this year as agentic coding loads on Claude surged, with surge pricing and per-user token limits kicking in to ration supply. Cursor, whose entire product runs on aggressive token consumption, has been transparent about the fact that token cost management is among the most important engineering disciplines in the company. Klarna, after deploying AI customer support at scale, recalibrated parts of the rollout when it realised the unit economics required tighter controls. These are not edge cases. They are the early signal of a much broader transition.
What is starting to take shape is a new operating regime, defined less by whether companies adopt the discipline than by the rate and depth at which they do. Volume math will force the shift on everyone eventually. But the early adopters compound a cost-base advantage with every routing decision that gets cheaper, every cache that hits, every workload that moves to an SLM or open-source equivalent. The late adopters inherit the inverse — a structurally higher cost base, layered with the engineering debt of retrofitting the same practices under pressure.
2. The Token Math — Why This Is Suddenly Material
The reason this shift is happening now is an arithmetic problem most enterprise AI teams have not fully reckoned with. Two forces are moving in opposite directions at once: per-token cost is collapsing, and volume is growing faster than that cost is falling. The net effect is that absolute token spend keeps rising, even as every individual unit of inference gets cheaper.
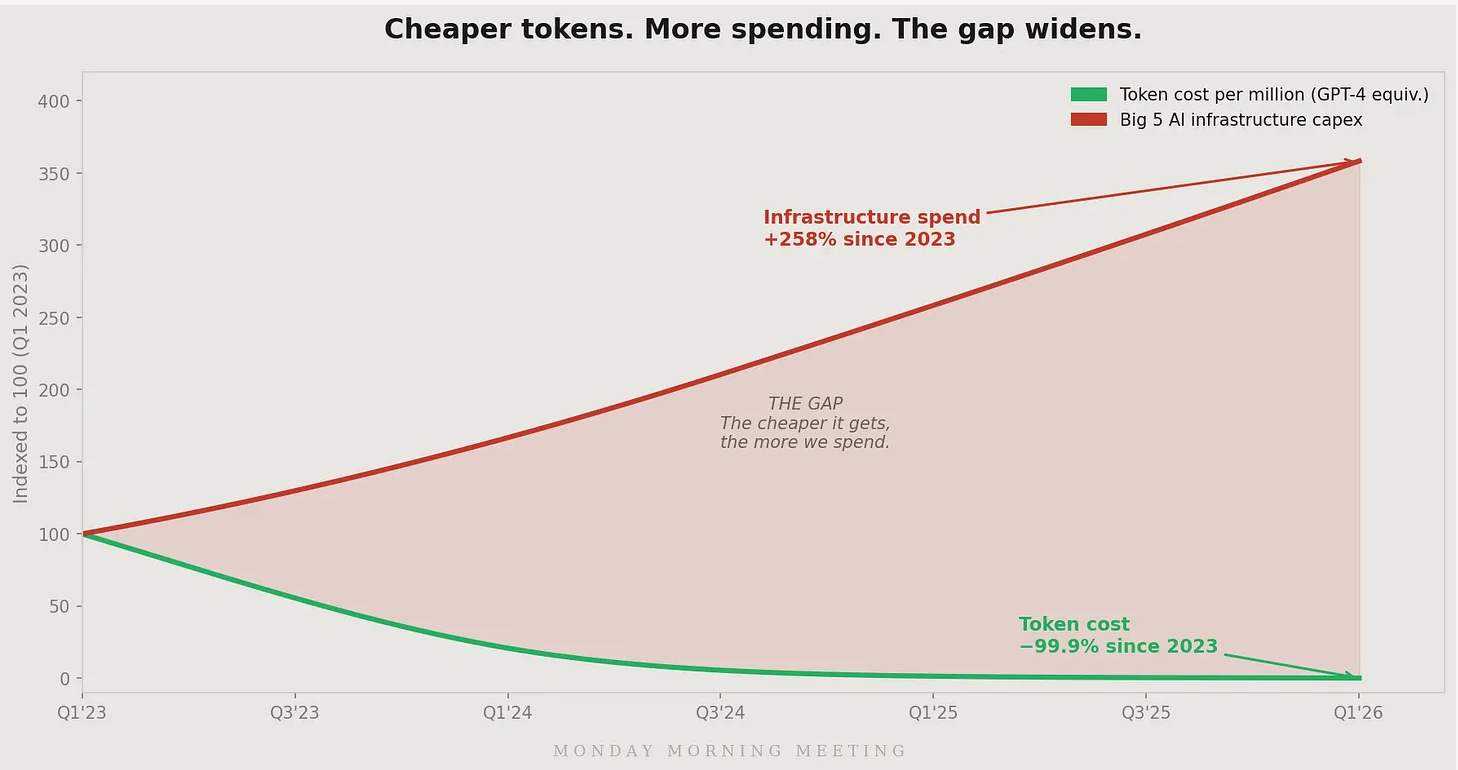
Token cost per call has collapsed. The cost of inference on GPT-4-class capability has fallen by more than 99 percent since 2022. Small Language Models — specialised, distilled, often open-source variants — can deliver competent output for between $150 and $800 per million conversations, against $15,000 to $75,000 on a frontier model. That is a roughly hundredfold cost differential for tasks where the SLM is genuinely competent. By every classical interpretation of input commodity economics, this should make AI cheaper to operate. And on a per-call basis, it does. What changes the picture is volume.
Token throughput is growing faster than per-token price is falling. The Coatue data shows roughly twelve times year-on-year volume growth across major API providers — substantially faster than the rate of cost compression. The net effect is that the absolute amount of money companies spend on tokens is rising, even as the unit cost falls. This is a textbook instance of the Jevons paradox: when a resource becomes more efficient, total consumption rises, often by more than the efficiency gain.
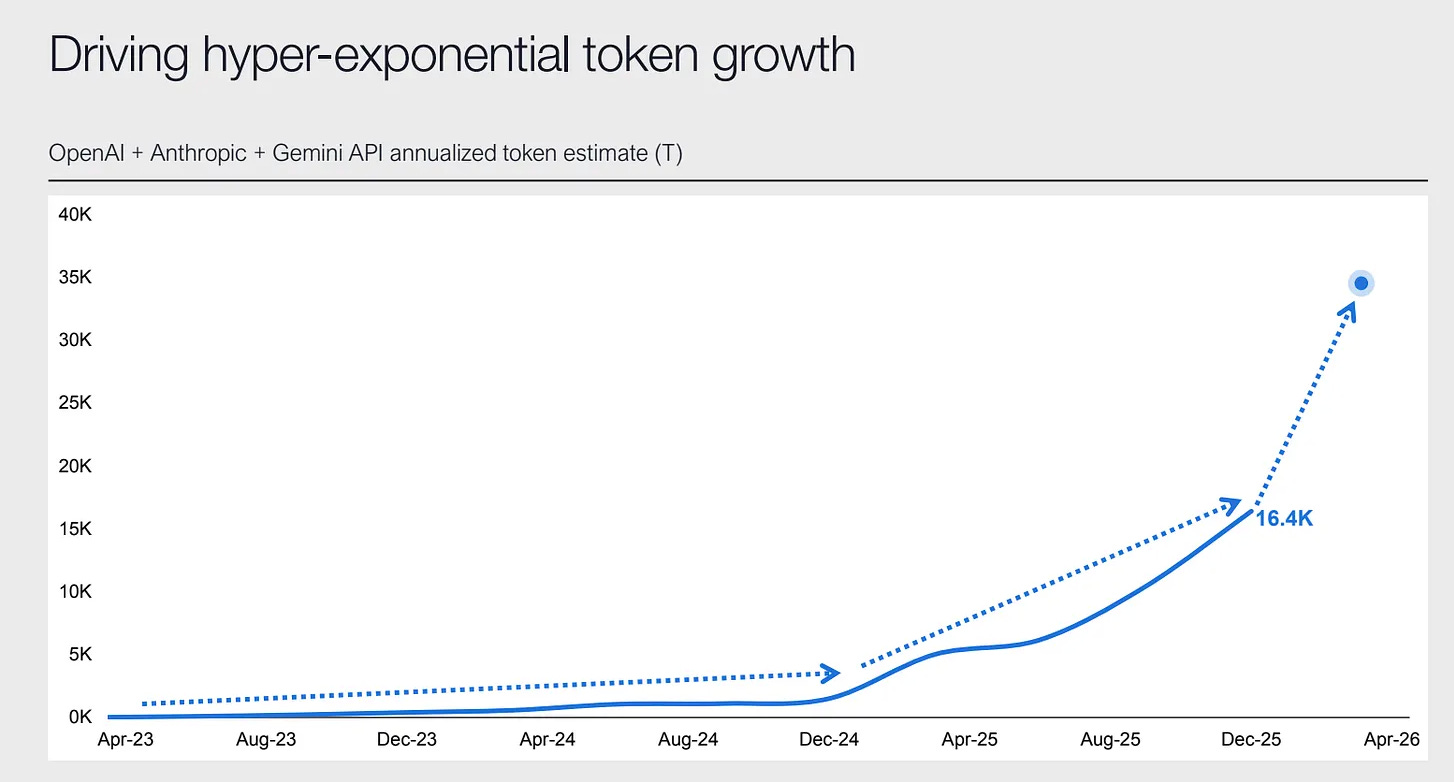
What makes this acutely material for enterprise buyers is the asymmetric way the volume growth distributes across use cases. Chat and assistant workloads grow more or less linearly with user adoption. Agentic workloads do not. A single autonomous research agent can consume in a few hours what a power user would consume in a year. A coding agent operating overnight can run up six-figure tabs across a developer team. A customer support agent operating at enterprise scale — handling millions of tickets per quarter — produces token consumption that bears no relationship to the conversational economics most enterprises projected when they signed their original API contracts.
The math, played forward, looks like this. Suppose a company has a thousand customer support agents handling roughly thirty conversations per day each — nine hundred thousand conversations per month. On a frontier model, the token bill for that workload runs between $13,500 and $67,500 per month, depending on conversation length and model choice. On a well-routed mix of frontier model for hard cases and SLM for routine ones, the same workload runs between $150 and $5,000 — depending on how aggressively the routing is tuned. That is a difference of roughly an order of magnitude in monthly cost, for the same operational outcome. For most enterprise deployments today, the gap between these two scenarios is the difference between an AI deployment that pays back inside a quarter and one that erodes margin for years without anyone noticing.
The same math holds at the consumer application layer, where it is even more acute. Cursor, the AI-native code editor, has been transparent about how aggressive its caching and routing strategies have to be — because at consumer pricing, every wasted token is a direct hit to contribution margin. ChatGPT’s free tier and Anthropic’s lower-tier offerings exist inside a strict cost envelope: the company has to deliver value within a per-user token budget that, in many segments, is barely sustainable even after the recent rounds of cost compression.
What this means in practice is that token efficiency has stopped being a back-office engineering concern. It has become a determinant of whether an AI deployment is financially viable at all. For application companies pricing against outcomes — which is the direction the entire category is moving in — falling token costs are a pure margin tailwind.
For companies still pricing against tokens, the inverse holds: the same per-call deflation that expands margin in outcome-priced businesses compresses revenue inside token-priced ones. The asymmetry between the two pricing structures is the most important commercial dynamic in the AI stack right now, and it widens every quarter. Sitting between them is the broader enterprise market, where token spend is genuinely material but still treated as a procurement decision rather than an engineering discipline. That’s about to converge as the agentic workload is about to make the discipline mandatory - moving from token maxing to token efficiency.
3. The Agentic Multiplier — Why Agents Specifically Are Breaking the Economics
The reason this is suddenly material is almost entirely the shift from chat to agents. Chat, for all its commercial impact, was a structurally bounded workload. Agents are not. Understanding why is the foundation for understanding the entire compression discipline this article describes.
Chat is bounded by human attention. A user types a question, waits for a response, reads it, and types another. Even a power user with multiple sessions running in parallel burns somewhere between ten and fifty thousand tokens per active day. The total token consumption of every employee in a company using ChatGPT all day scales roughly linearly with headcount, and the order of magnitude is comfortably in the thousands of dollars per user per year. It is a manageable number.
Agents break that scaling in three distinct ways:
The first is recursion. A serious agentic workflow rarely involves a single model call. It involves an orchestrating agent that calls sub-agents, each of which may call further sub-agents, each of which may invoke tools, each of which may return data that triggers more reasoning. A single user-facing request — “research the competitive landscape and prepare a briefing” — can produce hundreds of internal model calls before the user sees a result. The user did not type hundreds of times. The agent did, on the user’s behalf.
The second is context inflation. Every step in a multi-step agentic workflow needs to know what happened in the previous steps. The default architecture for managing this is to pass the entire context window forward at every step. A workflow that runs ten steps with twenty thousand tokens of context at each step burns two hundred thousand tokens of input — even before counting the model’s output at each step. Compressed context, retrieval-based context, and structured state are all attempts to fix this, but the default behaviour of most agent frameworks is to pay for context many times over the lifetime of a single task.
The third is reasoning depth. The newest generation of frontier models — Claude’s extended thinking, OpenAI’s o-series reasoning, Gemini’s thinking modes — produce dramatically better output by burning dramatically more internal compute on reasoning. A single reasoning call can produce ten thousand internal tokens of thought before generating a single visible output token. For high-value calls this is exactly the right trade — but it is not a one-to-one replacement for chat-era token economics. It is a structural increase in per-call cost that, multiplied across a recursive agentic workflow, can produce six-figure bills for a single complex task.
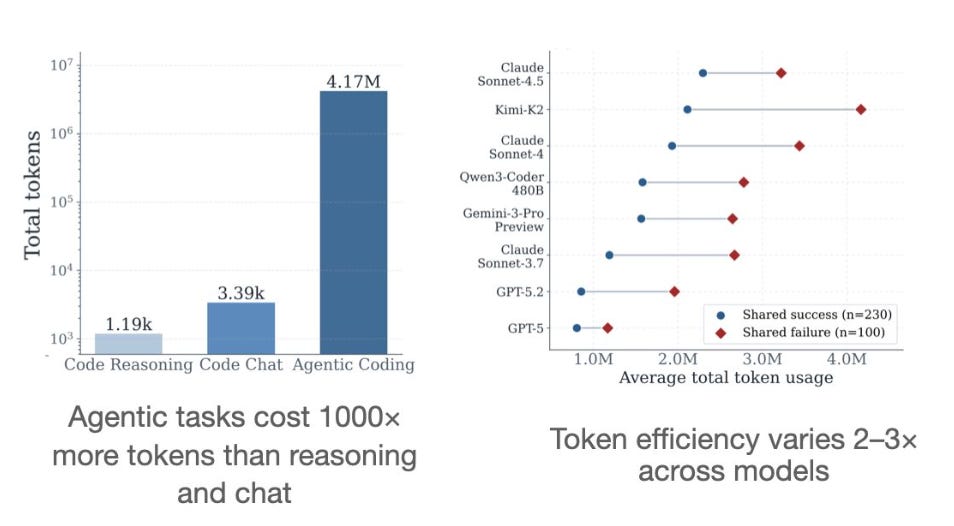
The math, taken together, is straightforward. A casual chat user might consume around fifty thousand tokens in a session. A single autonomous research agent task — recursing through sub-agents, passing context forward, using a reasoning model — can comfortably consume one to two million tokens. That is a forty-fold multiplier per task. Multiply that across a workflow that runs the same pattern hundreds of times per day, and the token consumption profile of an enterprise that has moved from chat to agents bears no resemblance to the consumption profile of an enterprise that is still on chat.
This is the dynamic that makes everything else in the article real. Without the agentic multiplier, token cost compression would still be happening, but the volume growth would not be outpacing it. Inference would simply be getting cheaper, and that would be the end of the story. With the agentic multiplier, the absolute cost is rising even as the unit cost falls — which is why the operating discipline has become urgent, why companies are racing to build control planes, and why the architecture of efficiency is becoming a board-level concern. The agentic workload is the forcing function and everything else in this article is downstream of it.
Some of you may have seen the uncanny story about an enterprise recently racking up a $500m monthly Claude code bill…. case in point to what I’m describing.
Article: An Enterprise Racks up $500m Monthly Claude Code Bill
4. The Control Plane in Practice — What Companies Are Actually Doing
What companies are actually building, beneath the headline of “token efficiency,” is a set of engineering practices that collectively form what the industry is increasingly calling the AI control plane. Chamath Palihapitiya has been among the more articulate voices framing this publicly, in his commentary on 8090 and the broader AI infrastructure thesis: a layer that sits between the application and the underlying model and handles routing, observability, governance, and cost — analogous to what Kubernetes did for containers, or cloud cost management did for cloud spend. The practices inside this layer fall into four categories.
The first is model selection and routing. The insight is that most enterprise workloads do not need frontier capability for most of their work. Andreessen Horowitz’s research suggests agentic systems spend 70 to 80 percent of their time on routine tasks — orchestration, tool calling, parsing — where a two-billion-parameter Small Language Model can deliver competent output at one to two percent of the cost of a frontier call. Multi-model routing infrastructure — Cloudflare’s AI Gateway, OpenRouter, LiteLLM, Martian, and the internal gateways built by large enterprises like Uber — is what makes this selection mechanical and continuous. The routing layer is, in operational terms, the heart of the harness around the model. Cursor’s mid-2025 restructuring of its pricing into tiered access — explicit token budgets per tier, usage-based overages for power users — is the consumer-facing version of the same discipline: the moment routing logic that previously sat invisible in the product had to be exposed directly to the customer.
Adjacent to routing sit two model-layer choices that compress cost further. Open source self-hosting fundamentally changes the cost structure of inference. A company running Llama, DeepSeek, or Qwen on its own infrastructure — through providers like Together AI or Fireworks — is paying for hardware time rather than per-token fees, which for high-volume workloads can be ten to a hundred times cheaper than the equivalent frontier API call. DeepSeek’s emergence has accelerated the dynamic: a model that delivers near-frontier capability runnable on commodity hardware fundamentally changes the calculation. Edge compute is the second architectural shift, and probably the more underappreciated of the two. The newest on-device silicon — Apple’s M-series, Qualcomm’s Snapdragon X with NPUs, Microsoft’s Copilot+ PCs — can run capable models locally with zero token cost. Apple Intelligence and the hybrid Private Cloud Compute architecture is the cleanest illustration: small queries run locally; complex queries get offloaded only when the device-side model is not confident.
The second category is runtime optimisation — making each call cheaper without changing which model is called. Semantic caching recognises that many inference requests are similar to requests the system has already answered; vector-embedding-based caches can eliminate 30 to 60 percent of inference calls outright in high-volume workloads. Prompt and context compression attacks the input side, reducing token consumption by 30 to 50 percent for the same effective output by stripping out redundant boilerplate, repeated few-shot examples, and conversation history the model does not need on every turn. Anthropic’s prompt caching, OpenAI’s structured output controls, and a growing set of open-source libraries are now standard parts of the production stack. Helicone, Langfuse, and several emerging observability platforms now provide both caching and compression as default layers.
The third category is infrastructure-layer cost optimisation. The hyperscaler-dominated GPU market is being meaningfully disrupted by a new generation of specialised AI infrastructure providers — Nebius, CoreWeave, Lambda Labs, Crusoe — offering GPU compute at prices substantially below AWS, Azure, and GCP. For companies running serious inference, the difference between a specialised provider and a hyperscaler can be 30 to 60 percent of total compute cost, with the gap widening as the new entrants build out capacity optimised specifically for AI workloads. Nebius in particular has positioned itself as the pure-play AI infrastructure alternative at European scale, partnering directly with Nvidia. The infrastructure layer is where some of the largest token-cost wins of the next two years will come from.
The fourth category is observability and per-team budgeting — the layer that ties everything together. The control plane is not just routing and caching; it is the monitoring layer that gives finance teams real-time visibility into who is consuming how many tokens, on which workloads, with what cost per outcome. Per-team token budgets, per-application rate limits, alerting on usage spikes, attribution back to specific product features — these are the operational levers that turn AI from an uncontrolled cost line into a managed one. Uber’s mid-2025 decision to institute a per-engineer cap of roughly $1,500 per month on Claude Code spend is the headline expression of this practice — instituted after individual developers were burning through tens of thousands of dollars of inference costs in a matter of weeks. The cap was not a cost-cutting measure. It was an acknowledgment that without explicit budgeting at the engineer level, AI tools at the developer-velocity end of the stack become structurally ungovernable.
Taken together, these practices point to the same structural conclusion: the control plane is on its way to becoming the cost optimisation centre of every serious business deploying AI. It is not a niche engineering concern or a procurement question. It is the operating layer where every routing decision, model choice, cache hit, and per-team budget compounds into either expanding or compressing gross margin. Understanding this layer is now essential — for any operator building inside an AI-deploying company, any investor underwriting one, and anyone watching the economics of the agentic transition take shape.
5. The Counter-Intuitive Case
If you read this article straight through and conclude that the right operating discipline is to spend less on tokens, you have read it incorrectly. The argument I have been making is not that token spend should be minimised. It is that token spend should be allocated. And the difference between those two framings is the difference between a company that captures the value of intelligence and a company that leaves most of it on the table.
The most common failure mode I expect to see over the next eighteen months is companies overcorrecting. The current narrative around enterprise AI is increasingly cost-conscious, and a generation of CFOs and CIOs is being trained to view token spend the way they viewed cloud spend in 2014: as a controllable cost line to be optimised aggressively. That instinct will be correct for most of the workload. It will be wrong for the workload that matters most.
The mathematics behind this is straightforward. In almost every agentic deployment I have seen, the value distribution across workloads is not linear — it is power-law. A small number of inference calls produce outsized impact. The customer escalation that, handled well, retains a million-pound account. The contract clause that, caught in review, prevents a regulatory penalty. The line of code that, written carefully, ships a security-critical product without a vulnerability. These calls are not a meaningful share of the volume. They are a meaningful share of the value.
For those calls, the right model is the most capable one available. The right amount of context is as much as the model can usefully process. The right level of caching is none — the answer needs to be fresh, generated against the specific situation, with maximum reasoning depth. The right discipline is not cost minimisation. It is the opposite: willingness to spend an order of magnitude more on the calls where the marginal value of intelligence vastly exceeds the marginal cost of the tokens.
This is the deeper reading of the architecture I described in Section 4. Multi-model routing is not just a mechanism for pushing routine work to cheaper models. It is equally a mechanism for routing high-value work to the most expensive model, with confidence. The harness is the layer that knows the difference. It knows that this support ticket is a tier-one routine query that should go to a small specialised model, and that one is from a customer with a £200,000 monthly contract whose retention depends on the answer being right. It knows that this contract has standard terms and can be summarised by a distilled model, and that one carries acquisition-level liability and needs the full reasoning capability of the frontier. Whether the harness routes up or routes down depends on the value of the call, not on a blanket cost ceiling imposed from above.
Vertical AI companies are the cleanest public examples of this discipline. Sierra in customer experience, Harvey in legal, Abridge in healthcare — all of them route the routine majority of their workload to cheaper, faster, often domain-specialised smaller models, and reserve frontier capability for the calls where the value at stake meaningfully exceeds the cost of getting them right. The cheap calls fund the willingness to spend at the high-value end. The two tiers operate as one system, and the system is what makes the unit economics of vertical AI hold up under scrutiny. The same architecture that compresses cost on the routine side is what enables the spend on the consequential side. Neither half works alone.
What this means in practice is that the companies which win the next decade will not be the ones with the lowest token spend. They will be the ones with the best ratio of token spend to value captured. In some workloads that ratio improves by spending less. In others, it improves dramatically by spending more. The category that has not yet been named — but that I expect to become a core executive metric over the next two years — is something like token allocation quality: a measure of how well an organisation matches the spend of intelligence to the value of the outcome.
The cheapest possible deployment is almost always one that has failed to identify the calls where capability matters most. The most expensive possible deployment is one that has applied frontier capability to everything, regardless of value. The discipline that compounds is in the middle — and the middle is harder to reach than either extreme, because it requires judgment, instrumentation, and continuous calibration against actual outcomes rather than the simplicity of a token cost line.
Token efficiency, properly understood, is not a minimisation problem. It is an allocation problem. The companies that solve the allocation problem first will run the deployments the rest of the market eventually copies — and they will do it not by spending less, but by spending better.
Conclusion
The shift this article describes is structural, not cyclical. The token-maxing era is ending — not because the technology has matured, but because the volume has outgrown the discipline. What comes next is something more recognisable: the standard operational machinery of running expensive infrastructure at scale. Routing. Caching. Observability. Per-team budgets. The control plane that ties them together.
The deeper observation, though, is the one that runs through every section of this piece. Cost discipline in the agentic era is not a function of how little you spend. It is a function of how clearly you understand the value of each call. The companies that get this right will open up a structural delta in gross margin the rest of the market will spend years trying to close. This is the same dynamic that defines Scale Economies in Hamilton Helmer's 7 Powers framework: as token spend per outcome falls below the cost of the work it replaces, the marginal cost of producing the next unit of output drops while the revenue per outcome holds. Margins expand. Pricing gets flexible. The competitive position compounds.
The economic logic underneath all of this is straightforward, and worth stating directly. Replacing human labour and human workflows with AI agents is one of the most powerful operational moves available to any company today — but only when the math actually works. If the token cost of running an agent exceeds the cost of the human work it replaces, the deployment is not a productivity gain; it is a cost increase dressed up as one. The entire discipline this article describes — routing, caching, allocation, the control plane — exists for one reason: to ensure the ROI from token spend stays positive. When that ratio holds, automation compounds. When it inverts, the deployment is a hidden tax on the business.
Michael, this is a very good deconstruction of the macroeconomic reality hitting the deployment layer. You are entirely correct that the "token-maxing" honeymoon is being killed by the unyielding arithmetic of agentic recursion and context inflation.
To push your thesis into production physics: the enterprise panic over the "Agentic Multiplier" is not merely a financial tracking problem; it is an epistemic bottleneck rooted in the mathematics of transformer attention normalisation. When an autonomous workflow repeatedly passes an unpruned, append-only history forward to preserve context across recursive steps, it triggers what we characterise as Softmax Dilution. Because total attention across a continuous vector space must always sum to exactly 1, expanding the sequence length L forces individual token weights to compress inversely at an asymptotic scaling rate of O(1/L).
The ultimate consequence of this isn't just an inflated infrastructure bill, it is Ontological Pollution. As demonstrated by recent attention normalisation research, models lose geometric separability for all but a tiny fraction of a long sequence. Beyond that envelope, representation distances drop sharply; the vector coordinates for your final, validated business logic and a rejected early-stage hallucination compress into the exact same semantic neighbourhood. The math makes the truth and the noise look identical.
This is why the "Control Plane" cannot simply act as an external router or a passive cache filter. It must evolve into a strict two-state engine that physically segregates the context of discovery from the context of justification. Generating massive test-time compute and recursive reasoning tokens is a structural dead end unless the orchestration framework has a localized protocol to execute an epistemic pull request, extract surviving constraints, and violently delete the messy active scratchpad via Destructive Compaction.
I’ve been writing on the systems-engineering frameworks required to navigate these exact attention boundaries and token-allocation dynamics over at ReasonVoyager (https://reasonvoyager.substack.com/ ). Take a look. Your perspective on "token allocation quality" is spot on.
I'd love to connect and trade notes on how we build architectures that force agents to cleanly forget the noise so they can actually scale the signal.